Update Teknologi Untuk Pengolahan Data merupakan sebuah perjalanan menarik menuju efisiensi dan inovasi dalam dunia informasi. Dari pengelolaan data besar (big data) hingga penerapan kecerdasan buatan (AI), perkembangan teknologi telah merevolusi cara kita mengumpulkan, menganalisis, dan memanfaatkan informasi. Artikel ini akan membahas berbagai aspek penting dari kemajuan ini, mulai dari arsitektur sistem pengolahan big data hingga tantangan etika dalam penggunaan algoritma pembelajaran mesin.
Kita akan menjelajahi berbagai teknologi terkini, seperti Hadoop dan Spark, serta platform komputasi awan seperti AWS, Azure, dan GCP. Selain itu, akan dibahas pula peran algoritma pembelajaran mesin, teknik enkripsi data, visualisasi data yang efektif, dan tren masa depan pengolahan data yang akan membentuk lanskap industri di tahun-tahun mendatang. Siap untuk menyelami dunia yang dinamis ini?
Perkembangan Teknologi Pengolahan Data Besar (Big Data)

Era digital telah menghasilkan lonjakan data yang luar biasa, memunculkan kebutuhan akan teknologi pengolahan data besar (Big Data) yang handal dan efisien. Pengolahan Big Data bukan hanya sekadar menyimpan data, tetapi juga menganalisisnya untuk menghasilkan wawasan berharga yang dapat mendukung pengambilan keputusan strategis di berbagai sektor.
Arsitektur Umum Sistem Pengolahan Big Data
Arsitektur sistem pengolahan Big Data umumnya terdiri dari beberapa komponen utama yang saling berinteraksi. Komponen tersebut meliputi: sumber data (data lakes, database relasional, sensor, dll.), sistem pengambilan data (data ingestion), penyimpanan data (distributed storage), sistem pemrosesan data (Hadoop, Spark, dll.), sistem analitik (machine learning, data mining), dan visualisasi data (dashboard, report). Interaksi yang efisien antar komponen ini sangat penting untuk memastikan kinerja sistem yang optimal.
Teknologi Terbaru untuk Pengelolaan Big Data
Dunia teknologi Big Data terus berkembang pesat. Berikut tiga teknologi terbaru yang menonjol:
- Apache Kafka: Sebuah sistem streaming data yang memungkinkan pengolahan data real-time dengan kecepatan dan skalabilitas tinggi. Kelebihannya terletak pada kemampuannya menangani volume data yang sangat besar dengan latensi rendah, sehingga sangat cocok untuk aplikasi yang membutuhkan respon cepat seperti analisis sentimen media sosial atau pemantauan sistem.
- Graph Databases (Neo4j, Amazon Neptune): Database yang menyimpan data dalam bentuk graf, sangat efektif untuk menganalisis hubungan antar data. Kelebihannya adalah kemampuannya untuk memproses query yang kompleks yang melibatkan hubungan antar entitas, misalnya untuk menganalisis jaringan sosial atau rekomendasi produk.
- Data Virtualization: Teknologi yang memungkinkan akses dan pengolahan data dari berbagai sumber data yang berbeda tanpa perlu menggabungkan data tersebut secara fisik. Kelebihannya adalah fleksibilitas dan efisiensi, karena data tetap berada di lokasi asalnya, mengurangi kompleksitas dan biaya integrasi data.
Perbandingan Hadoop dan Spark dalam Menangani Big Data
Hadoop dan Spark merupakan dua framework yang populer untuk pengolahan Big Data, namun keduanya memiliki pendekatan yang berbeda. Hadoop, dengan model MapReduce-nya, lebih cocok untuk pengolahan data batch yang besar. Sementara Spark, dengan arsitektur in-memory processing, lebih cepat dan efisien untuk pengolahan data secara real-time dan iteratif.
| Fitur | Hadoop | Spark |
|---|---|---|
| Kecepatan Pemrosesan | Relatif Lambat | Sangat Cepat |
| Model Pemrosesan | Batch Processing | Batch dan Real-time Processing |
| Penggunaan Memori | Disk-based | In-memory |
| Kompleksitas | Relatif Kompleks | Relatif Sederhana |
Perbandingan Platform Cloud Computing untuk Pengolahan Big Data
Berbagai platform cloud computing menawarkan solusi Big Data yang komprehensif. Berikut perbandingan tiga platform yang populer:
| Fitur | AWS | Azure | GCP |
|---|---|---|---|
| Fitur Utama | EMR, S3, Redshift | HDInsight, Azure Data Lake Storage, Azure Synapse Analytics | Dataproc, Cloud Storage, BigQuery |
| Biaya | Bergantung pada penggunaan sumber daya | Bergantung pada penggunaan sumber daya | Bergantung pada penggunaan sumber daya |
| Skalabilitas | Sangat Skalabel | Sangat Skalabel | Sangat Skalabel |
Skenario Penggunaan Teknologi Big Data dalam Sektor Ritel
Di sektor ritel, teknologi Big Data dapat digunakan untuk meningkatkan pengalaman pelanggan dan efisiensi operasional. Misalnya, analisis data transaksi pelanggan dapat digunakan untuk memprediksi tren penjualan, mengoptimalkan penempatan produk, dan memberikan rekomendasi produk yang personal.
Contohnya, sebuah perusahaan ritel dapat menggunakan data transaksi, data demografis pelanggan, dan data interaksi pelanggan di website atau aplikasi mobile untuk membangun model prediksi permintaan produk. Model ini dapat membantu perusahaan mengoptimalkan stok barang, mengurangi kerugian akibat stok yang berlebihan atau kekurangan, dan meningkatkan kepuasan pelanggan dengan menyediakan produk yang tepat pada waktu yang tepat.
Algoritma dan Pembelajaran Mesin dalam Pengolahan Data

Pengolahan data modern sangat bergantung pada algoritma dan pembelajaran mesin (machine learning) untuk meningkatkan efisiensi dan akurasi. Kemampuan untuk menganalisis data dalam skala besar dan menemukan pola yang kompleks telah merevolusi berbagai sektor, dari ritel hingga perawatan kesehatan. Pembelajaran mesin, sebagai cabang kecerdasan buatan, memungkinkan komputer untuk belajar dari data tanpa diprogram secara eksplisit, menghasilkan solusi yang lebih cerdas dan adaptif.
Peran Algoritma Pembelajaran Mesin dalam Meningkatkan Efisiensi Pengolahan Data
Algoritma pembelajaran mesin secara signifikan meningkatkan efisiensi pengolahan data dengan otomatisasi tugas-tugas yang sebelumnya membutuhkan intervensi manusia yang intensif. Contohnya, algoritma dapat mengidentifikasi pola dalam data yang besar dan kompleks jauh lebih cepat dan akurat daripada manusia, memungkinkan pengambilan keputusan yang lebih cepat dan tepat. Selain itu, algoritma ini mampu menangani data dalam volume yang sangat besar, yang melampaui kemampuan manusia untuk memproses secara manual. Otomatisasi ini juga mengurangi kesalahan manusia dan memastikan konsistensi dalam pengolahan data.
Perbedaan Pembelajaran Terawasi, Pembelajaran Tanpa Pengawasan, dan Pembelajaran Penguatan
Terdapat tiga pendekatan utama dalam pembelajaran mesin, masing-masing dengan karakteristik dan penerapan yang berbeda.
- Pembelajaran Terawasi (Supervised Learning): Algoritma dilatih dengan data yang telah diberi label, di mana input dan output yang diinginkan telah diketahui. Model belajar untuk memetakan input ke output yang benar. Contoh: Klasifikasi gambar (mengenali kucing dan anjing berdasarkan gambar yang telah diberi label “kucing” atau “anjing”).
- Pembelajaran Tanpa Pengawasan (Unsupervised Learning): Algoritma dilatih dengan data yang tidak diberi label, dan tujuannya adalah untuk menemukan pola dan struktur tersembunyi dalam data. Contoh: Pengelompokan pelanggan berdasarkan perilaku pembelian mereka (clustering).
- Pembelajaran Penguatan (Reinforcement Learning): Algoritma belajar melalui interaksi dengan lingkungan, menerima reward atau penalty berdasarkan tindakannya. Tujuannya adalah untuk memaksimalkan reward kumulatif. Contoh: Algoritma yang mengontrol robot untuk menyelesaikan tugas tertentu, seperti berjalan atau bermain game.
Dampak Deep Learning pada Pengolahan Data
Deep learning, subbidang dari pembelajaran mesin yang menggunakan jaringan saraf tiruan dengan banyak lapisan (deep), telah menghasilkan kemajuan signifikan dalam pengolahan data. Kemampuannya untuk mempelajari representasi data yang kompleks dan hierarkis memungkinkan deep learning untuk mencapai akurasi yang tinggi dalam berbagai tugas, seperti pengenalan citra, pemrosesan bahasa alami, dan prediksi deret waktu. Contohnya, deep learning digunakan dalam sistem rekomendasi untuk memprediksi preferensi pengguna dan dalam deteksi fraud untuk mengidentifikasi transaksi yang mencurigakan.
Penerapan Algoritma Clustering dalam Menganalisis Data Pelanggan
Algoritma clustering, seperti K-Means, dapat digunakan untuk mengelompokkan pelanggan berdasarkan karakteristik demografis, perilaku pembelian, atau preferensi mereka. Misalnya, sebuah perusahaan ritel dapat menggunakan algoritma clustering untuk mengidentifikasi segmen pelanggan yang berbeda, seperti pelanggan yang sering membeli produk tertentu, pelanggan yang sensitif terhadap harga, atau pelanggan yang loyal terhadap merek. Informasi ini kemudian dapat digunakan untuk mengembangkan strategi pemasaran yang lebih efektif dan personalisasi.
Sebagai ilustrasi, bayangkan sebuah perusahaan telekomunikasi yang memiliki data pelanggan yang meliputi usia, lokasi, jumlah penggunaan data, dan tagihan bulanan. Dengan menggunakan algoritma K-Means, perusahaan dapat mengelompokkan pelanggan menjadi beberapa segmen, misalnya: segmen pelanggan muda dengan penggunaan data tinggi, segmen pelanggan senior dengan penggunaan data rendah, dan segmen pelanggan dengan tagihan bulanan tinggi. Setiap segmen ini dapat ditargetkan dengan strategi pemasaran yang berbeda.
Tantangan Etika dalam Penggunaan Algoritma Pembelajaran Mesin untuk Pengolahan Data
Penggunaan algoritma pembelajaran mesin dalam pengolahan data menimbulkan sejumlah tantangan etika yang penting. Bias dalam data pelatihan dapat menghasilkan output yang diskriminatif, sementara kurangnya transparansi dalam pengambilan keputusan algoritma dapat menimbulkan masalah akuntabilitas. Penting untuk memastikan bahwa algoritma dikembangkan dan digunakan secara bertanggung jawab, dengan mempertimbangkan implikasi etika dan sosialnya.
Keamanan Data dan Privasi dalam Era Digital

Pengolahan data yang masif di era digital membawa konsekuensi penting: keamanan data dan privasi pengguna menjadi perhatian utama. Ancaman keamanan siber terus berkembang, menuntut strategi perlindungan data yang komprehensif dan beradaptasi dengan cepat. Oleh karena itu, pemahaman yang mendalam tentang ancaman, teknik perlindungan, dan regulasi terkait menjadi krusial.
Ancaman Keamanan Data Utama
Berbagai ancaman keamanan mengintai data kita. Serangan siber, mulai dari serangan brute force sederhana hingga serangan yang lebih canggih seperti ransomware dan phishing, dapat membahayakan integritas, kerahasiaan, dan ketersediaan data. Selain itu, akses internal yang tidak sah, kesalahan manusia, dan bahkan bencana alam juga dapat menyebabkan kebocoran atau kerusakan data. Perlu diingat bahwa kerentanan sistem, baik perangkat lunak maupun perangkat keras, seringkali menjadi pintu masuk bagi para pelaku kejahatan siber.
Teknik Enkripsi Data
Enkripsi merupakan metode kunci dalam melindungi informasi sensitif. Teknik ini mengubah data yang dapat dibaca (plaintext) menjadi bentuk yang tidak dapat dibaca (ciphertext) tanpa kunci dekripsi yang tepat. Beberapa teknik enkripsi yang umum digunakan antara lain:
- Enkripsi Simetris: Menggunakan kunci yang sama untuk enkripsi dan dekripsi. Contohnya adalah AES (Advanced Encryption Standard).
- Enkripsi Asimetris: Menggunakan sepasang kunci, yaitu kunci publik untuk enkripsi dan kunci privat untuk dekripsi. Contohnya adalah RSA (Rivest-Shamir-Adleman).
- Hashing: Mengubah data menjadi nilai hash yang unik, satu arah, dan tidak dapat dibalik untuk memverifikasi integritas data.
Pemilihan teknik enkripsi yang tepat bergantung pada kebutuhan keamanan dan jenis data yang dilindungi.
Update teknologi pengolahan data kini semakin pesat, terutama dalam bidang kecerdasan buatan. Salah satu aplikasinya yang menarik adalah pengembangan chatbot, yang memudahkan interaksi manusia-mesin. Bagi Anda yang tertarik mempelajari pembuatannya, silakan kunjungi Panduan Membuat Chatbot Sederhana untuk panduan lengkap dan praktis. Kemajuan dalam pengolahan data besar (big data) juga mendukung perkembangan chatbot yang lebih canggih dan responsif, menunjukkan sinergi antara teknologi pengolahan data dan kecerdasan buatan.
Kepatuhan terhadap Regulasi Privasi Data
Regulasi privasi data, seperti GDPR (General Data Protection Regulation) di Eropa dan CCPA (California Consumer Privacy Act) di California, menetapkan standar ketat untuk pengumpulan, penggunaan, dan perlindungan data pribadi. Kepatuhan terhadap regulasi ini sangat penting untuk menghindari denda yang besar dan menjaga kepercayaan pengguna. Hal ini meliputi transparansi dalam pengumpulan data, hak akses pengguna terhadap data mereka, dan mekanisme keamanan yang kuat untuk melindungi data tersebut.
Perkembangan teknologi pengolahan data kini begitu pesat, memungkinkan analisis data yang lebih kompleks dan akurat. Bayangkan saja, aplikasi Game Balapan Bertema Jalan Raya modern memanfaatkan teknologi ini untuk menciptakan pengalaman bermain yang lebih realistis, dengan simulasi fisika yang canggih dan rendering grafis yang detail. Kemajuan ini menunjukkan bagaimana pengolahan data yang efisien mendukung pengembangan berbagai aplikasi, dari hiburan hingga industri yang lebih serius.
Protokol Keamanan Komprehensif
Sebuah protokol keamanan yang komprehensif mencakup berbagai lapisan perlindungan. Hal ini meliputi:
| Elemen Keamanan | Penjelasan |
|---|---|
| Firewall | Mencegah akses yang tidak sah ke jaringan. |
| Sistem Deteksi Intrusi (IDS) | Mendeteksi aktivitas mencurigakan di jaringan. |
| Sistem Pencegahan Intrusi (IPS) | Mencegah serangan siber secara aktif. |
| Otentikasi Multi-Faktor (MFA) | Menambahkan lapisan keamanan tambahan untuk verifikasi identitas. |
| Enkripsi Data | Melindungi data yang disimpan dan ditransmisikan. |
| Backup dan Recovery | Memastikan data dapat dipulihkan jika terjadi kehilangan data. |
| Pembaruan Keamanan Berkala | Menambal kerentanan keamanan pada sistem. |
Sistem Deteksi Intrusi
Sistem Deteksi Intrusi (IDS) berfungsi sebagai pengawas keamanan jaringan, memantau lalu lintas jaringan untuk mendeteksi aktivitas yang mencurigakan. IDS dapat bekerja secara berbasis jaringan (Network-based IDS) atau berbasis host (Host-based IDS). Ketika IDS mendeteksi aktivitas mencurigakan, seperti pola serangan yang dikenal atau anomali dalam lalu lintas jaringan, ia akan mengirimkan peringatan kepada administrator sistem. Sistem ini membantu dalam mengidentifikasi dan menanggapi ancaman keamanan sebelum mereka menyebabkan kerusakan yang signifikan. Contohnya, IDS dapat mendeteksi upaya akses yang tidak sah ke server database dan mengirimkan peringatan kepada administrator, memungkinkan tindakan segera untuk memblokir akses tersebut.
Visualisasi Data dan Analisis: Update Teknologi Untuk Pengolahan Data
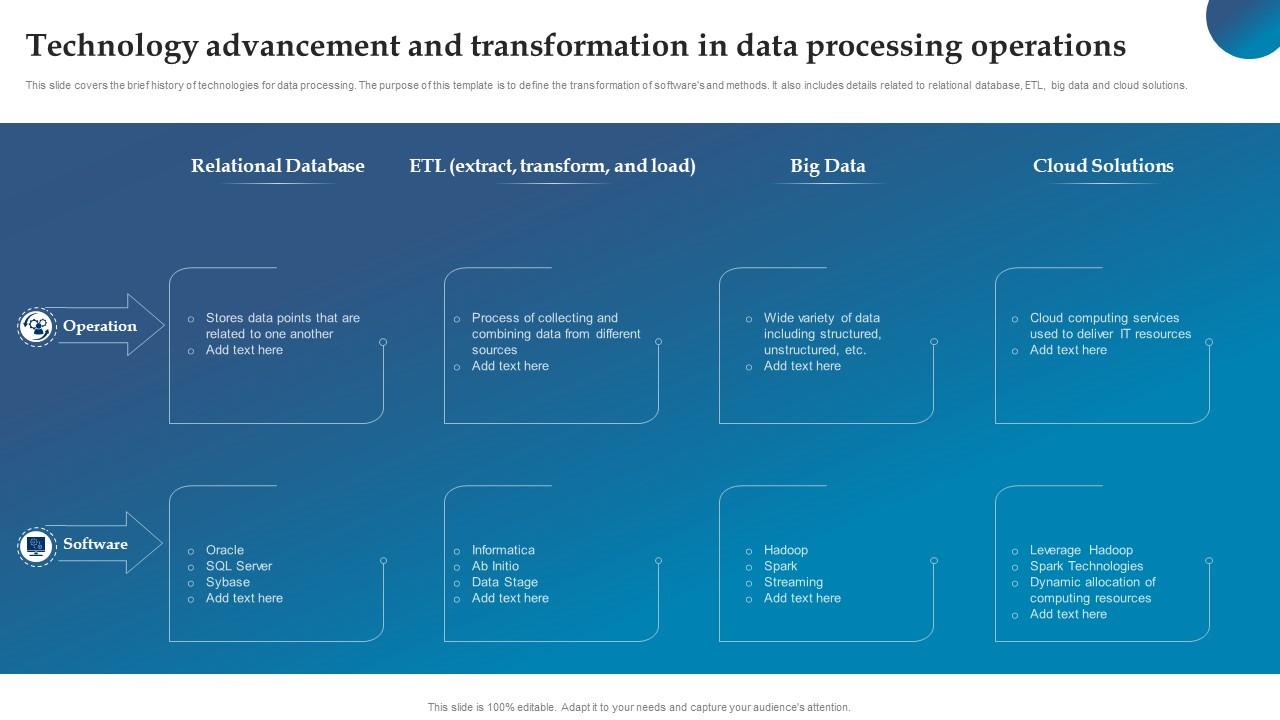
Visualisasi data merupakan kunci untuk memahami informasi kompleks yang terkandung dalam dataset besar. Dengan mengubah data mentah menjadi representasi visual, kita dapat mengidentifikasi tren, pola, dan anomali yang mungkin terlewatkan jika hanya menganalisis data dalam bentuk tabel atau angka. Analisis data, khususnya analisis eksploratif, berperan penting dalam mengarahkan proses visualisasi dan memastikan interpretasi yang akurat.
Teknik Visualisasi Data yang Efektif
Berbagai teknik visualisasi data tersedia, masing-masing cocok untuk jenis data dan tujuan tertentu. Pemilihan teknik yang tepat sangat penting untuk menyampaikan informasi secara efektif dan menghindari kesalahpahaman.
- Grafik Batang (Bar Chart): Ideal untuk membandingkan nilai-nilai kategorikal.
- Grafik Garis (Line Chart): Menunjukkan tren dan perubahan data seiring waktu.
- Grafik Pie (Pie Chart): Memperlihatkan proporsi bagian dari keseluruhan.
- Scatter Plot: Menunjukkan hubungan antara dua variabel numerik.
- Heatmap: Menampilkan data dalam bentuk warna, ideal untuk menunjukkan korelasi atau kepadatan data.
- Map: Menunjukkan data geografis.
Contoh Visualisasi Tren Pertumbuhan Penjualan
Misalnya, untuk menunjukkan tren pertumbuhan penjualan perusahaan selama lima tahun terakhir, kita dapat menggunakan grafik garis. Sumbu X mewakili tahun (2019, 2020, 2021, 2022, 2023), sementara sumbu Y menunjukkan nilai penjualan dalam jutaan rupiah. Warna garis dapat dipilih sesuai dengan branding perusahaan, misalnya biru tua untuk mewakili stabilitas dan pertumbuhan. Grafik akan menunjukkan fluktuasi penjualan dari tahun ke tahun, dengan harapan menunjukkan tren peningkatan secara keseluruhan.
Alat dan Perangkat Lunak Visualisasi Data
Sejumlah alat dan perangkat lunak populer tersedia untuk membantu dalam proses visualisasi data. Pemilihan alat bergantung pada kebutuhan, kompleksitas data, dan kemampuan teknis pengguna.
- Tableau: Sangat populer untuk pembuatan dashboard interaktif dan visualisasi data yang kompleks.
- Power BI: Pilihan yang kuat dan terintegrasi dengan ekosistem Microsoft.
- Qlik Sense: Dikenal dengan kemampuan analisis data yang mendalam.
- Python dengan library Matplotlib dan Seaborn: Memberikan fleksibilitas tinggi untuk kustomisasi visualisasi.
- R dengan library ggplot2: Alternatif populer di kalangan statistisi dan data scientist.
Langkah-langkah Membuat Dashboard Visualisasi Data Interaktif
- Menentukan Tujuan: Tentukan informasi apa yang ingin disampaikan melalui dashboard.
- Memilih Alat: Pilih perangkat lunak visualisasi data yang sesuai.
- Membersihkan dan Memproses Data: Pastikan data akurat dan terstruktur dengan baik.
- Memilih Visualisasi yang Tepat: Pilih jenis grafik yang paling efektif untuk setiap bagian informasi.
- Merancang Tata Letak: Atur elemen visualisasi dengan cara yang mudah dipahami dan menarik.
- Menambahkan Interaktivitas: Tambahkan fitur filter, sorotan, dan navigasi untuk meningkatkan pengalaman pengguna.
- Menguji dan Menyempurnakan: Uji dashboard dan lakukan penyesuaian berdasarkan umpan balik.
Langkah-langkah Analisis Data Eksploratif (EDA)
Analisis data eksploratif (EDA) bertujuan untuk memahami karakteristik data, mengidentifikasi pola, dan menemukan wawasan sebelum melakukan analisis yang lebih formal.
- Memahami Data: Pelajari variabel, tipe data, dan ukuran dataset.
- Membersihkan Data: Tangani data yang hilang, outlier, dan inkonsistensi.
- Mencari Pola: Gunakan visualisasi dan statistik deskriptif untuk mengidentifikasi tren dan pola.
- Membuat Hipotesis: Kembangkan hipotesis berdasarkan temuan EDA.
- Menguji Hipotesis: Lakukan analisis statistik lebih lanjut untuk menguji hipotesis.
Tren Masa Depan Pengolahan Data
Dunia pengolahan data bergerak dengan sangat cepat. Lima tahun mendatang akan menyaksikan transformasi signifikan dalam cara kita mengumpulkan, menganalisis, dan memanfaatkan data. Perkembangan teknologi terus mendorong batas-batas kemampuan pengolahan data, membuka peluang baru sekaligus menghadirkan tantangan yang perlu diatasi.
Tiga Tren Utama Pengolahan Data dalam Lima Tahun Mendatang
Beberapa tren utama akan membentuk lanskap pengolahan data dalam lima tahun ke depan. Ketiga tren ini saling berkaitan dan akan berdampak signifikan pada berbagai industri.
- Peningkatan Penggunaan Kecerdasan Buatan (AI) dan Machine Learning (ML): AI dan ML akan semakin terintegrasi dalam proses pengolahan data, memungkinkan otomatisasi tugas-tugas kompleks, analisis prediktif yang lebih akurat, dan pengambilan keputusan yang lebih cerdas. Contohnya, dalam perawatan kesehatan, AI dapat digunakan untuk mendiagnosis penyakit lebih cepat dan akurat berdasarkan analisis citra medis.
- Perkembangan Komputasi Edge: Pengolahan data akan semakin bergeser ke “edge,” yaitu lebih dekat ke sumber data. Ini akan mengurangi latensi, meningkatkan efisiensi, dan memungkinkan aplikasi real-time yang lebih handal. Misalnya, dalam manufaktur, sensor di mesin dapat memproses data secara lokal untuk mendeteksi masalah dan melakukan penyesuaian segera, tanpa harus mengirimkan data ke pusat data yang jauh.
- Data Streaming dan Analisis Real-Time: Kemampuan untuk memproses data secara real-time akan semakin penting. Alat dan teknik analisis data streaming akan memungkinkan pengambilan keputusan yang lebih cepat dan responsif terhadap perubahan kondisi. Contohnya, perusahaan e-commerce dapat menggunakan analisis real-time untuk menyesuaikan harga produk berdasarkan permintaan dan tren pasar.
Dampak Kecerdasan Buatan (AI) pada Pengolahan Data
Kecerdasan buatan akan menjadi pengubah permainan utama dalam pengolahan data. Kemampuan AI untuk mempelajari pola, memprediksi tren, dan mengotomatiskan tugas-tugas rumit akan meningkatkan efisiensi dan akurasi analisis data secara drastis.
Sebagai contoh, AI dapat digunakan untuk mendeteksi anomali dalam data yang mungkin terlewatkan oleh manusia, membantu dalam pendeteksian fraud, prediksi pemeliharaan peralatan, dan personalisasi layanan pelanggan. Namun, penting untuk mempertimbangkan aspek etika dan bias dalam algoritma AI untuk memastikan keadilan dan transparansi.
Peran Komputasi Kuantum dalam Pengolahan Data
Komputasi kuantum, meskipun masih dalam tahap pengembangan awal, berpotensi merevolusi pengolahan data. Kemampuan komputer kuantum untuk memproses sejumlah besar data secara simultan dapat memecahkan masalah yang saat ini tidak dapat diatasi oleh komputer klasik.
Dalam konteks pengolahan data, komputasi kuantum dapat digunakan untuk mengembangkan algoritma yang lebih efisien untuk optimasi, simulasi, dan analisis data yang kompleks. Meskipun implementasinya masih beberapa tahun lagi, potensi dampaknya pada bidang seperti farmasi (penemuan obat baru) dan keuangan (model prediksi pasar yang lebih akurat) sangat besar.
Transformasi Industri oleh Teknologi Pengolahan Data
Teknologi pengolahan data akan mengubah berbagai industri secara mendalam. Berikut contohnya:
| Industri | Dampak Teknologi Pengolahan Data |
|---|---|
| Perawatan Kesehatan | Diagnosis penyakit yang lebih akurat, personalisasi pengobatan, pengembangan obat baru yang lebih efisien, dan manajemen perawatan kesehatan yang lebih efektif. |
| Manufaktur | Peningkatan efisiensi produksi, prediksi pemeliharaan peralatan, optimasi rantai pasokan, dan peningkatan kualitas produk. |
| Keuangan | Deteksi fraud yang lebih akurat, manajemen risiko yang lebih baik, dan pengembangan strategi investasi yang lebih cerdas. |
Tantangan dan Peluang Implementasi Teknologi Pengolahan Data Baru, Update Teknologi Untuk Pengolahan Data
Adopsi teknologi pengolahan data baru menghadirkan tantangan dan peluang. Tantangan utama meliputi biaya implementasi yang tinggi, kebutuhan akan keahlian khusus, dan masalah keamanan data. Namun, peluangnya sangat besar, termasuk peningkatan efisiensi, pengambilan keputusan yang lebih baik, dan inovasi di berbagai sektor.
Penting untuk mengembangkan strategi yang komprehensif untuk mengatasi tantangan tersebut, termasuk investasi dalam pelatihan dan pengembangan sumber daya manusia, pengembangan standar keamanan data yang kuat, dan kolaborasi antara industri, akademisi, dan pemerintah.
Simpulan Akhir

Perkembangan teknologi pengolahan data terus berlanjut dengan pesat, menawarkan peluang luar biasa namun juga tantangan yang kompleks. Memahami arsitektur sistem, algoritma pembelajaran mesin, aspek keamanan data, dan teknik visualisasi yang efektif merupakan kunci untuk memanfaatkan potensi penuh dari data. Dengan mengadopsi pendekatan yang komprehensif dan etis, kita dapat memastikan bahwa teknologi pengolahan data berkontribusi pada kemajuan dan kesejahteraan masyarakat.